본 게시글의 원문은 Yann Debray의 MATLAB with Python Book 입니다. 해당 책은 MIT 라이센스를 따르기 때문에 개인적으로 번역하여 재배포 합니다. 본 포스팅에는 추후 유료 수익을 위한 광고가 부착될 수도 있습니다.
MIT License
Copyright (c) 2023 Yann Debray
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
본 게시물에서 활용된 소스 코드들은 모두 Yann Debray의 GitHub Repo에서 확인할 수 있습니다.
6.2. MATLAB 앱을 사용한 AI 개발 촉진
6.2.1. 데이터 클리너 앱
AI 파이프라인의 첫 번째 단계는 종종 데이터를 정리하는 것입니다. 이 과정에서는 데이터 분석가가 조작 중인 변수를 이해하기 위해 어느 정도의 상호작용이 필요합니다. 데이터의 입력 형식이 고정되면 이 과정을 자동화하여 전체 데이터셋에 확장할 수 있습니다.
챕터 2의 날씨 데이터를 예로 들어보겠습니다. 첫 번째 예제에서는 -nodesktop 모드(엔진의 기본 모드)로 MATLAB을 시작합니다. 다음 두 섹션에서는 -desktop 모드를 사용하여 MATLAB 데스크탑을 통해 데이터와 상호작용하고 이미 실행 중인 MATLAB 세션에 연결하는 방법을 보여줍니다.
환경 설정
!git clone https://github.com/hgorr/weather-matlab-python
import matlab.engine
m = matlab.engine.start_matlab()
m.cd('weather-matlab-python') # 이전 디렉토리 위치 반환
# m.cd('..')
'C:\\Users\\ydebray\\Downloads\\python-book-github'
m.pwd()
'C:\\Users\\ydebray\\Downloads\\python-book-github\\weather-matlab-python'
# Python 인터프리터가 따라오도록 확인
import os
os.getcwd()
os.chdir('weather-matlab-python')
# os.chdir('..')
날씨 데이터 가져오기
import weather
appid ='b1b15e88fa797225412429c1c50c122a1'
json_data = weather.get_forecast('Muenchen','DE',appid,api='samples')
data = weather.parse_forecast_json(json_data)
data.keys()
dict_keys(['current_time', 'temp', 'deg', 'speed', 'humidity', 'pressure'])
print(len(data['temp']))
data['temp'] [0:5]
36
[286.67, 285.66, 277.05, 272.78, 273.341]
t = matlab.double(data['temp'])
t
matlab.double([[286.67,285.66,277.05,272.78,273.341,275.568,276.478,276.67,278.253,276.455,275.639,275.459,275.035,274.965,274.562,275.648,277.927,278.367,273.797,271.239,269.553,268.198,267.295,272.956,277.422,277.984,272.459,269.473,268.793,268.106,267.655,273.75,279.302,279.343,274.443,272.424]])
timetable 형식으로 변환
# 데이터 정리를 위한 timetable로 변환
m.workspace['data'] = data
m.eval("TT = timetable(datetime(string(data.current_time))',cell2mat(data.temp)','VariableNames',{'Temp'})",nargout=0)
m.who()
['TT', 'data']
앱과 수동으로 상호작용
m.dataCleaner(nargout=0)
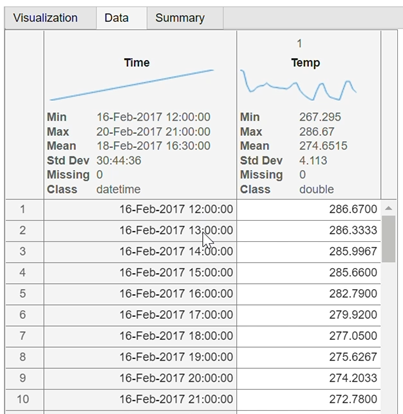
앱이 나타나면 빈 캔버스가 표시되며 데이터를 가져올 수 있는 옵션이 제공됩니다. 워크스페이스에서 timetable을 선택하십시오.
이렇게 하면 데이터가 앱의 메인 뷰에 열립니다:
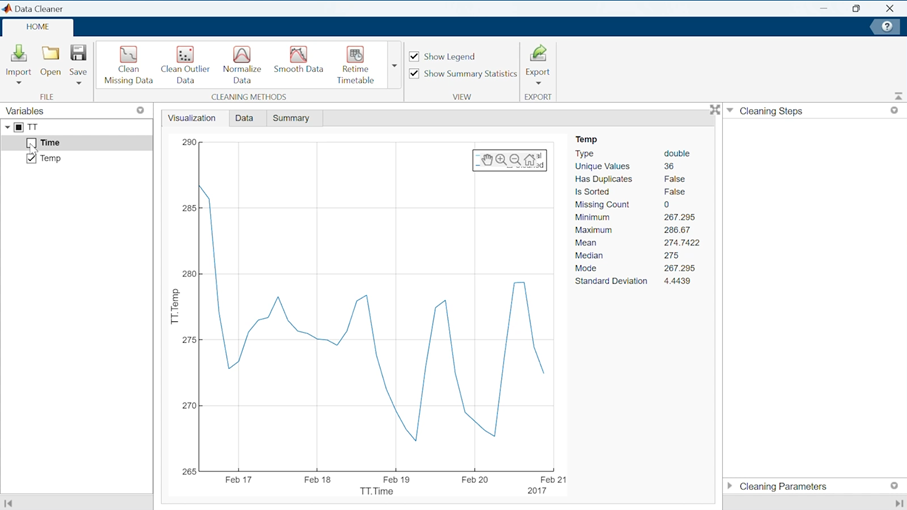
왼쪽 패널에서 시각화하고 조작하려는 변수를 선택할 수 있습니다.
우리는 시간 변수를 선택하고 Retime Timetable 정리 방법을 사용할 것입니다:

이렇게 하면 오른쪽 패널에 새로운 샘플링, 시간 간격: 1시간을 지정할 수 있는 옵션이 표시됩니다. 결과에 만족하면 수락(오른쪽 하단)을 클릭하십시오.
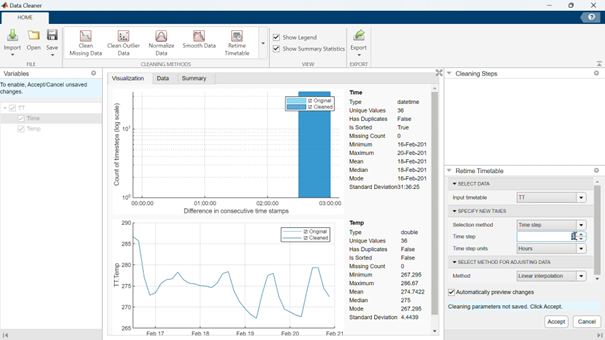
중앙 패널의 탭을 변경하여 데이터 변환 결과를 확인할 수 있습니다:
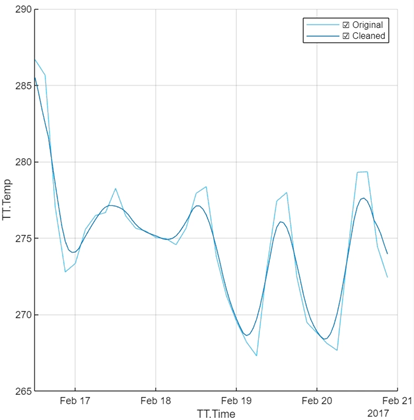
두 번째 변환은 데이터 평활화입니다.

평활화 방법을 선택할 수 있으며(기본 이동 평균을 사용) 평활화 계수를 조정할 수 있습니다.
정리 단계 내보내기 데이터 모양에 만족하면 수동 작업을 함수로 저장하여 들어오는 새로운 날씨 데이터에 적용하여 전처리를 자동화할 수 있습니다.
function TT = preprocess(TT)
% Retime Timetable
TT = retime(TT,"regular","linear","TimeStep",hours(1));
% 입력 데이터 평활화
TT = smoothdata(TT,"movmean","SmoothingFactor",0.25);
end
이 함수를 Python에서 호출하고 작동하는지 테스트할 수 있습니다.
TT = m.workspace['TT']
TT2 = m.preprocess(TT)
m.parquetwrite("data.parquet",TT2,nargout=0)
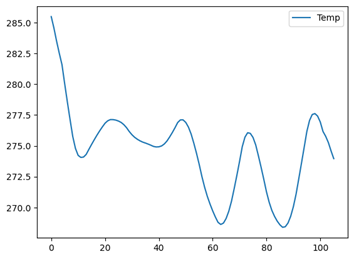
import pandas as pd
pd.read_parquet('data.parquet').plot(y='Temp')
6.2.2. 회귀 및 분류 학습자 앱
Scikit-Learn 샘플 데이터셋의 일부인 보스턴 주택 예제를 사용하여 Python에서 MATLAB을 호출합니다. Jupyter 노트북을 열고 Python에서 실행 중인 MATLAB 세션에 연결합니다:
import matlab.engine
m = matlab.engine.connect_matlab()
데이터셋 가져오기
import sklearn.datasets
dataset = sklearn.datasets.load_boston()
dataset.keys()
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename', 'data_module'])
data = dataset['data']
target = dataset['target']
사용 중인 MATLAB 버전에 따라 데이터 및 타겟 배열을 MATLAB 더블로 변환해야 할 수 있습니다:
- 22a 이전: Numpy 배열이 수락되지 않으므로 목록으로 변환해야 합니다.
- 22a에서는 Numpy 배열을 MATLAB 객체 생성자(double, int32, …)에 전달할 수 있습니다.
- 22b부터는 Numpy 배열을 MATLAB 함수에 직접 전달할 수 있습니다.
# 22a 이전
X_m = matlab.double(data.tolist())
Y_m = matlab.double(target.tolist())
# 22a에서는
X_m = matlab.double(data)
Y_m = matlab.double(target)
# 22b부터는
X_m = data
Y_m = target
# Python에서 전달된 데이터로 회귀 학습자 앱 호출
m.regressionLearner(X_m,Y_m,nargout=0)
세션은 전달된 데이터로 회귀 학습자에서 자동으로 생성됩니다:
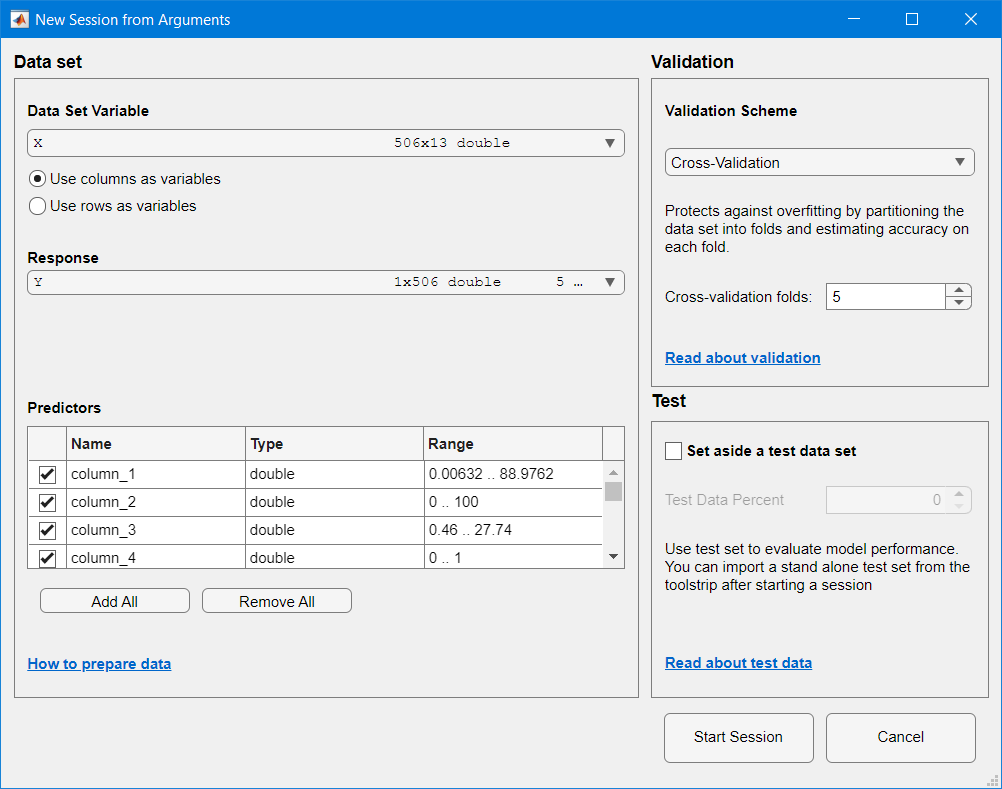
여러 모델과 카테고리를 선택할 수 있습니다:

훈련 중에 특정 지표를 시각화할 수 있습니다:

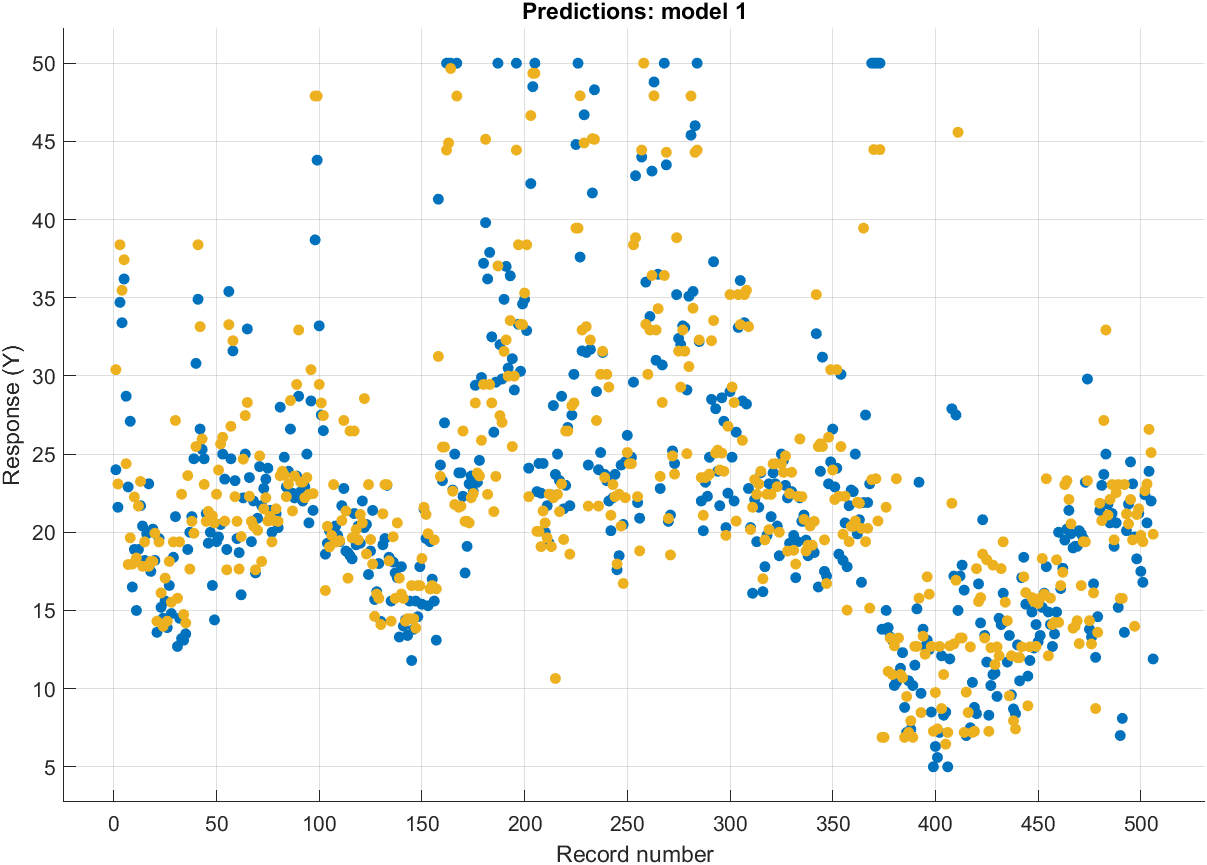
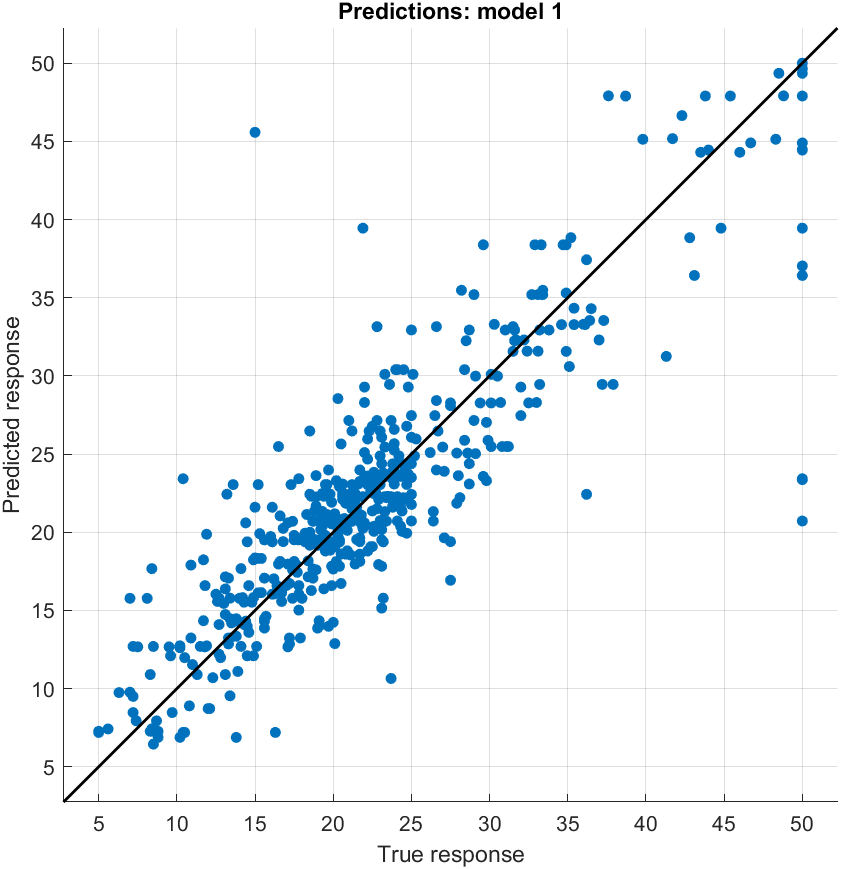
훈련한 모델 중 하나에 만족하면 함수를 생성하거나 내보낼 수 있습니다:
정보는 MATLAB 명령 창에 공유됩니다:
변수가 기본 워크스페이스에 생성되었습니다. ‘trainedModel’ 구조가 회귀 학습자에서 내보내졌습니다. 새로운 예측자 열 행렬 X에 대해 예측하려면: yfit = trainedModel.predictFcn(X) 자세한 내용은 내보낸 모델을 사용하여 예측하는 방법을 참조하십시오.
마지막으로, 모델을 가져와 Python에서 예측 함수를 변수에 할당할 수 있습니다:
model = m.workspace['trainedModel']
m.fieldnames(model)
['predictFcn', 'RegressionTree', 'About', 'HowToPredict']
predFcn = model.get('predictFcn')
이렇게 하면 Python 내에서 직접 모델을 테스트할 수 있습니다:
X_test = data[0]
y_test = target[0]
X_test,y_test
(array([6.320e-03, 1.800e+01, 2.310e+00, 0.000e+00, 5.380e-01, 6.575e+00,
6.520e+01, 4.090e+00, 1.000e+00, 2.960e+02, 1.530e+01, 3.969e+02,
4.980e+00]),
24.0)
m.feval(predFcn,X_test)
23.46666666666667
다른 모델을 반복하고 테스트하여 예측이 테스트 타겟에 더 가까운지 확인할 수 있습니다.
6.2.3. 이미지 라벨러 앱
데이터 준비는 머신 러닝 및 딥 러닝 애플리케이션 개발의 핵심입니다. ML 모델에 얼마나 많은 노력을 기울이든, 모델이 소비할 데이터를 준비하는 데 적절한 시간을 투자하지 않으면 성능이 저조할 가능성이 큽니다. 이 예제에서는 딥 러닝 애플리케이션을 위해 라벨을 지정할 이미지 세트로 시작합니다.
import os
cwd = os.getcwd()
vehicleImagesPath = os.path.join(cwd, "..", "images", "vehicles", "subset")
그런 다음 MATLAB 엔진 API를 Python에서 시작하고 이미지 라벨러 앱을 열어 이미지 위치를 입력으로 전달합니다:
import matlab.engine
m = matlab.engine.connect()
m.imageLabeler(vehicleImagesPath, nargout=0)
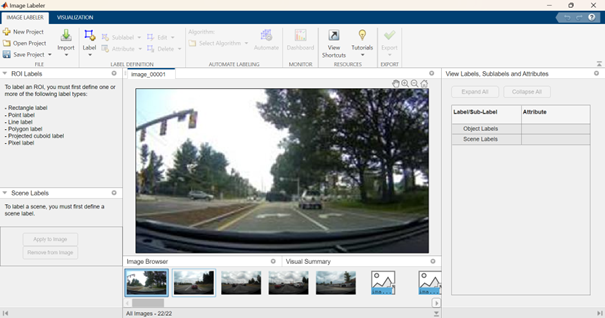
앱이 Python으로 출력 인수를 반환하지 않기 때문에 nargout=0(출력 인수 수는 0)을 지정해야 합니다.
이제 상호작용적으로 새로운 ROI 라벨을 생성할 수 있습니다:
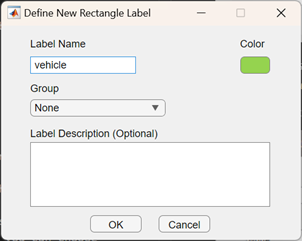
그리고 차량을 수동으로 라벨링하기 시작합니다:
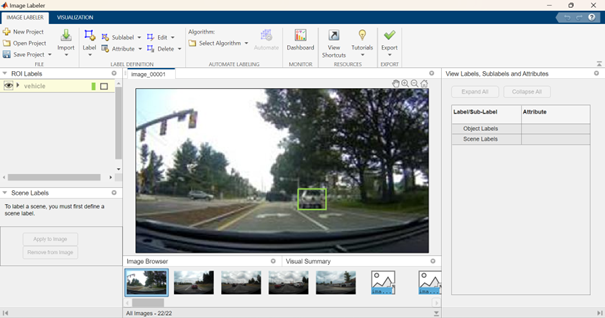
이 과정은 상당히 지루하며, 특히 딥 러닝 워크플로우를 위해 필요한 라벨링된 이미지 수가 많을 수 있습니다. 따라서 다음은 라벨링 프로세스를 자동화(또는 반자동화)하여 라벨링을 용이하게 하는 방법을 보여줍니다. 자동으로 라벨링하려는 이미지를 선택한 후 다양한 알고리즘(예: ACF 차량 감지기, ACF 사람 감지기 또는 사용자 정의 감지기 가져오기) 중에서 선택할 수 있습니다. 이 경우, ACF 차량 감지기를 선택한 후 선택한 이미지가 자동으로 라벨링됩니다. 이전에 언급했듯이 이 과정은 반자동화된 것이며, 모든 차량을 감지하지 못하거나 내보내기 전에 일부 경계 상자를 수정하고 싶을 수 있습니다.
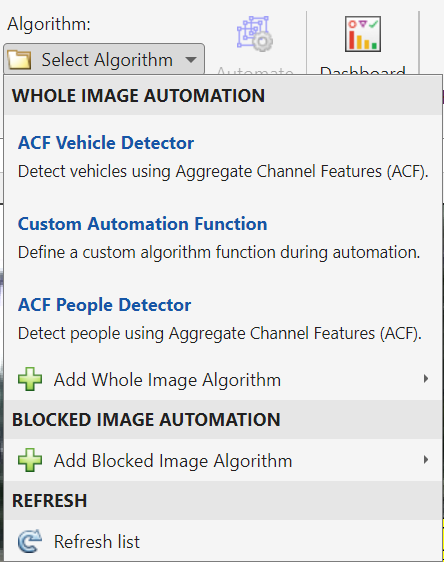
마지막으로 라벨링 프로세스를 MATLAB 테이블로 내보내 Python에서 작업을 계속하십시오:
Python으로 돌아와서 관심 있는 변수를 수집합니다:
imageFilename = m.eval("gTruth.imageFilename")
labels = m.eval("gTruth.vehicle")
그리고 작업을 계속할 수 있는 편리한 형태로 만듭니다:
import pandas as pd
import numpy as np
# 데이터를 DataFrame으로 편리한 형태로 가져옴
labels = [np.array(x) for x in labels]
df = pd.DataFrame({"imageFileName":imageFilename, "vehicle":labels})
라벨링된 데이터는 이제 파일 위치 및 각 차량의 경계 상자에 대한 정보가 포함된 DataFrame으로 편리하게 형성되었으며 쉽게 접근할 수 있습니다:
df.iloc[[13]]
m.exit()